URL構造を理解する。Webディレクターやエンジニアは必見!
URL構造を解説(ホスト、ディレクトリ、パラメータとは?)
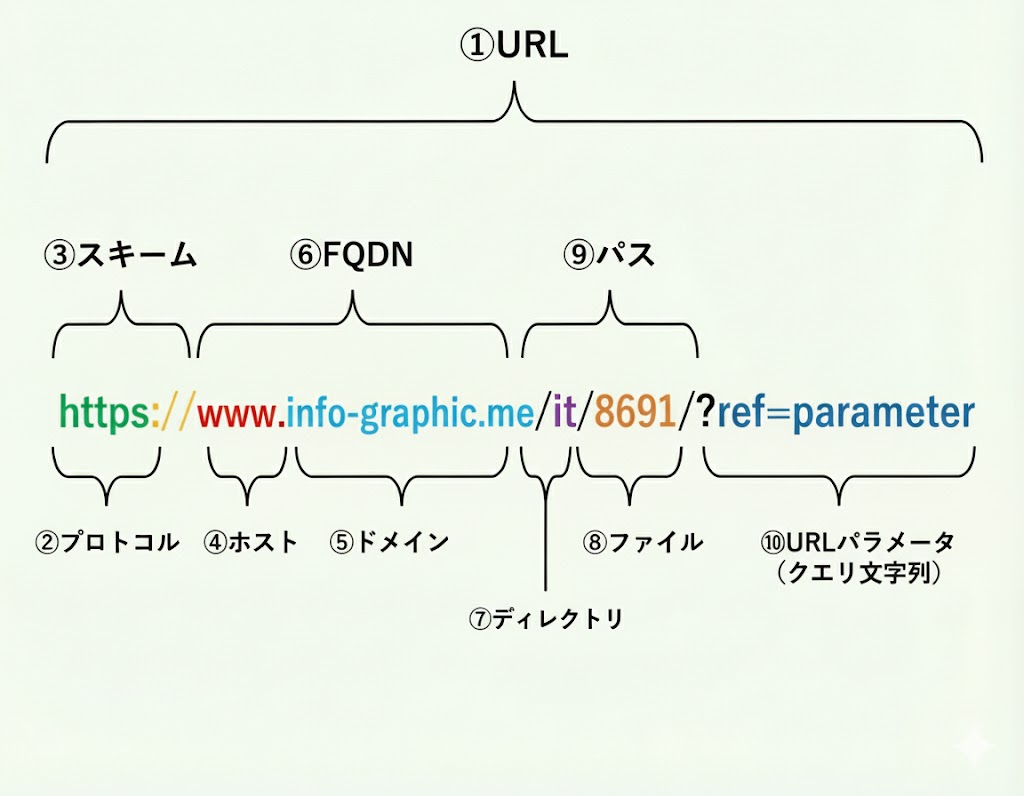
① URLとは?
URL(Uniform Resource Locator)は、インターネット上の“住所”を表す文字列。
どのサーバーの、どの場所の、どのデータを取得するかをブラウザに伝える。
今回の例ではhttps://www.info-graphic.me/it/8691/?ref=parameter
がその URL になる。
② プロトコルとは?
ネットワークで通信するための“決まりごと”のこと。
Web では HTTP や HTTPS が代表的。
今回の URL の https は「HTTPS という方式で通信せよ」という意味。
③ スキームとは?
URL の先頭にある「どの方式(プロトコル)でアクセスするか」を示す部分。https:// がスキームで、ブラウザに「暗号化通信でアクセスしてね」と指示している。
④ ホストとは?
アクセス先のサーバーを指す名前。
今回の例では www.info-graphic.me がホストで、このサーバーに向けて通信が行われる。
⑤ ドメインとは?
インターネット上の“サイト名に相当する識別名”。
ホスト名の一部でもあり、サイトや組織を識別する役割を持つ。
今回の URL では info-graphic.me がドメイン。
⑥ FQDNとは?
Fully Qualified Domain Name(完全修飾ドメイン名)の略で、
ホスト名まで含めて“そのサーバーを一意に特定できる名前”。
今回だと www.info-graphic.me が FQDN にあたる。
⑦ ディレクトリとは?
サーバー内でファイルやページを整理する“フォルダ”の概念。
URL では / で区切られた部分のうち、ファイル名ではない部分がディレクトリ。
今回だと it がディレクトリに相当。
⑧ ファイルとは?
サーバーに存在する実体のあるデータ(HTML、画像、PDFなど)。
URL の末尾にファイル名が書かれることが多いが、今回の /8691/ のようにディレクトリを指定してファイルを省略しているケースもある(多くは index.html が裏で読まれる)。
⑨ パスとは?
ドメイン以下の「どの場所にあるページか」を示す道筋のこと。
今回の URL のパスは /it/8691/。
これによりサーバー内のどの位置にあるリソースを読むかが決まる。
⑩ URLパラメータ(クエリ文字列)とは?
URL の最後に付ける“追加情報”で、? から始まる部分に書かれる。
今回では ?ref=parameter がそれ。
「どこから来たか」「条件指定」「検索ワード」などをサーバーに伝える用途で使われる。
URL構造は誰が考えた?
URLは誰が考えた?
- 発案者:ティム・バーナーズ=リー
- 時期:1990年前後
- 所属:CERN(欧州原子核研究機構)
- 目的:研究者同士が文書へアクセスしやすいよう、Web上にある情報の「住所」を統一的に表す仕組みとして作られた。
補足:なぜURLが必要だった?
- 当時はネットワークや文書形式がバラバラで、
「どこに何があるか」を一つのルールで示す仕組みがなかった。 - そこで、アクセス方法(プロトコル)+場所(ホスト・パス) を一つの文字列で表す「URL」を定義した。
URLと同時期に作られたもの
- HTTP(Web閲覧のプロトコル)
- HTML(Webページの記述言語)
- Webブラウザの最初の形
全部まとめてティムが作ったので、実質「Webの父」。
URL構造のトリビア
■ 1. 「://」は本当は別に必要じゃなかった
URLの https:// にある「://」は、
ティム・バーナーズ=リー自身が「ちょっとややこしくしすぎた」と後から後悔した記号。
本当は もっと簡単な区切りでも良かった とインタビューで語っている。
■ 2. 「www」は義務じゃない
URLの先頭にある「www」はただのサブドメイン。
Web初期の慣習としてつけていた名残で、
有っても無くてもOK(example.com だけで全然良い)。
■ 3. URLの長さに正式な上限はない
技術的に「何文字まで」というルールはなく、
実際の制限はブラウザやサーバーの都合。
例えば:
- 古いIE:2,083文字
- Chrome:20万文字以上いける
(ただし実用性ゼロ)
■ 4. 「?」より後は全部サーバー任せ
?key=value のクエリ文字列は ルールのようでほぼルールじゃない。
形式上「?以降でパラメータ」というだけで、
本当にどう解釈するかはサーバー側の自由。
なので開発者ごとに書き方がバラバラになりがち。
■ 5. スラッシュの有無で別ページ扱いになる
https://example.com/page とhttps://example.com/page/ は 別URL。
(後ろの / をディレクトリとみなすかどうかの違い)
昔はSEOでも議論のタネだった。
■ 6. 「index.html」は特別扱いされる
ディレクトリにアクセスした時、
サーバーはデフォルトで index.html (または index.php など)を探して返す。
だからhttps://example.com/ とhttps://example.com/index.html
は同じページになることが多い。
■ 7. 国別ドメイン(.jp, .uk)は元々メール用ではなく「地域管理のため」
国コード(ccTLD)は 国連とISOの国コードがベース。
URLが生まれる前から標準化されていた。
■ 8. URLは実は「URI」という大きな概念の一部
URL=「場所を示すURI」
URN=「名前を示すURI」
実は昔から専門家はURLよりURIを使いたがる。
URL構造を図解で理解する
インフォグラフィックから読み解く
インフォグラフィックはクリックすると拡大できます
ドメインについて深堀
ドメインとは?
インターネット上の住所を示す名前。
右側ほど上位になる階層構造で成り立っている。
例:www.example.co.jp
・jp(トップレベルドメイン)
・co(セカンドレベル)
・example(第三階層)
・www(サブドメイン)
トップレベルドメイン(TLD)とは?
ドメイン名の一番右側部分。
例:.com.jp.net.org など。
TLDは大きく3種類に分類される。
1. gTLD(汎用トップレベルドメイン)
国に紐づかない一般用途のTLD。
代表例:.com、.net、.org、.info、.biz、.xyz
現在は誰でも自由に使える。
豆知識:.com は “company” ではなく “commercial” が語源。
2. ccTLD(国コードトップレベルドメイン)
国や地域に割り当てられた2文字のTLD。
例:.jp(日本)、.us(アメリカ)、.uk(イギリス)、.cn(中国)、.fr(フランス)
日本の .jp の特徴
・管理団体:JPRS
・日本国内住所が必要(信頼性が高い)
・属性型(co.jp、or.jp、go.jp など)と汎用jpがある
属性型の例
・co.jp:日本の企業のみ
・or.jp:財団・組合など
・go.jp:日本の政府機関
特に co.jp は信頼性が高く企業サイトに多い。
3. 新gTLD(2012年以降追加されたTLD)
ICANNのルール変更で大量に追加された種類。
例:.tokyo、.app、.shop、.blog、.site、.ninja、.camera、.google(ブランド専用)
1000種類以上存在し、個性を出しやすい。
ただし信頼性や認知度は従来の .com や .jp より弱いケースもある。
ドメインの階層構造の基本ルール
- 一番右が TLD
- 左に向かってセカンドレベル → サードレベル → サブドメイン
- 早い者勝ちで取得でき、更新しないと失効する
SEO的にどのTLDが有利?
Google公式見解:
「TLDによるランキング差はない」
ただし実務では
・.com → 認知度が高くクリック率が安定
・.jp / co.jp → 日本国内での信頼性が非常に高い
・新gTLD → 覚えにくいものはクリック率が低下しがち
という“人間側の反応の違い”が影響することがある。